

Intelligenza Artificiale
Architetture AI on-premise, LLM locali, RAG, agenti autonomi. L’intelligenza che non si può permettere di vedere spenta va posseduta.
Scopri →
Open Source
Il contributo di noze all’ecosistema Open Source: progetti, strumenti e pubblicazioni rilasciati con licenze permissive.
Scopri →
Admina Enterprise
Governance AI Open Source: audit trail, PII redaction, policy bidirezionali ALLOW/BLOCK/REDACT su qualsiasi modello, locale o remoto.
Scopri Admina →
Ricerca & Sviluppo
Ricerca applicata e prototipazione, dall’AI all’infrastruttura, in collaborazione con università e centri di ricerca.
Scopri →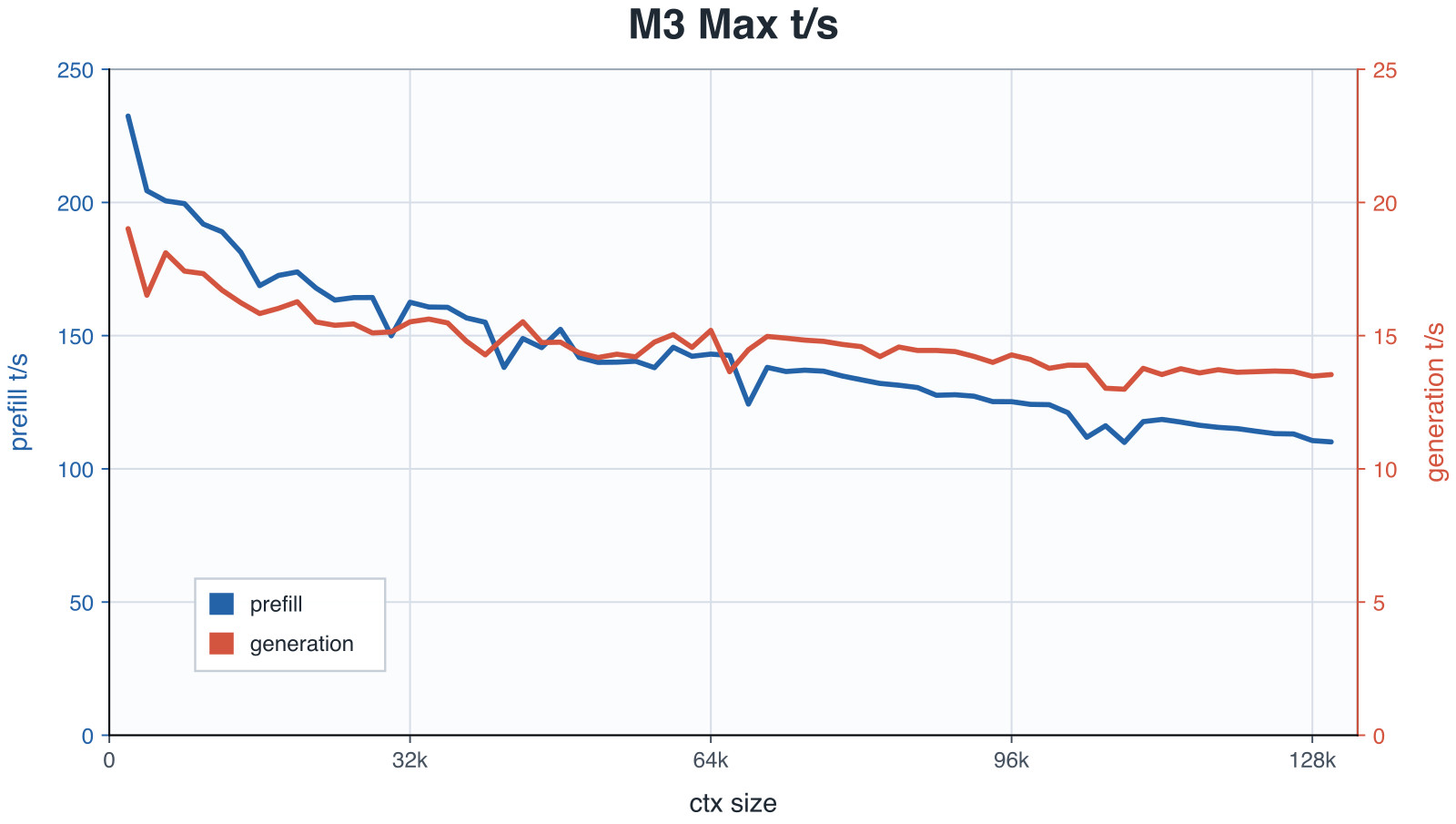
Cos’è DwarfStar 4
DwarfStar 4 (ds4) è un motore di inferenza nativo scritto da antirez (Salvatore Sanfilippo, il creatore di Redis), ottimizzato per far girare in locale DeepSeek V4 Flash, con supporto per DeepSeek V4 PRO su macchine con molta memoria. Non è un runner generico per file GGUF né un wrapper attorno a un altro runtime: è completamente self-contained, una scommessa volutamente stretta su un modello alla volta.
L’obiettivo dichiarato è un’esperienza di AI locale “finita” da capo a fondo: caricamento del modello, rendering dei prompt, tool calling, gestione della KV cache (in RAM e su disco), API server e un agente di coding integrato, pronti per essere usati dalla CLI o dai coding agent. Il codice è rilasciato con licenza MIT ed è scritto in gran parte in C, con i kernel per Metal (macOS, il target primario), CUDA (incluso il DGX Spark) e ROCm (Strix Halo, come il Framework Desktop). Il progetto riconosce esplicitamente il debito verso llama.cpp e GGML.
In poche parole: prende un modello a pesi aperti quasi di frontiera e lo fa funzionare bene su un computer personale di fascia alta.
La scommessa tecnica: 2 bit, ma fatti bene
Il punto che rende ds4 interessante è la quantizzazione a 2 bit asimmetrica. Invece di comprimere tutto in modo uniforme, ds4 quantizza in modo aggressivo solo gli esperti della parte MoE (Mixture of Experts) instradata, che occupano la maggior parte dello spazio del modello, lasciando intatti i componenti più delicati (esperti condivisi, proiezioni, routing). Antirez usa la formula di un “recipe di quant 2/8 bit estremamente asimmetrico”, che permette di far stare il modello in 96 o 128 GB di RAM.
Il risultato non è un giocattolo. Sui benchmark del progetto, su un MacBook Pro M3 Max la generazione si mantiene intorno ai 13-15 token al secondo e il prefill resta sopra i 100 token al secondo, fino a 128k token di contesto (vedi il grafico qui sopra). Sono cifre del progetto, da prendere come indicative dell’hardware specifico, ma più che sufficienti per un uso reale.
La KV cache come “cittadino del disco”
C’è un’idea architetturale che vale la pena sottolineare. ds4 tratta la KV cache come un cittadino di prima classe del disco, non solo della RAM. Combinando le KV cache compresse di DeepSeek V4 con gli SSD velocissimi dei Mac moderni e lo SSD streaming, la quantità di RAM smette di essere un muro (“riesco a far girare questo modello, sì o no?”) e diventa uno spettro continuo di livelli di velocità. È un cambio di prospettiva che amplia di molto l’insieme delle macchine su cui un modello grande è praticabile, e che si sposa con l’hardware “GPU in a box” come il DGX Spark di cui abbiamo già scritto a proposito delle workstation AI on-premise.
Il progetto include anche API compatibili con OpenAI e Anthropic, tool calling, speculative decoding (MTP), inferenza distribuita su più macchine e vector steering per guidare il comportamento del modello. È codice beta, nato in pochi giorni, ma con un perimetro funzionale già molto ampio.
Sviluppato con l’AI, dichiarato apertamente
Un dettaglio che antirez mette in chiaro: ds4 è stato sviluppato con forte assistenza di GPT 5.5, con gli umani a guidare idee, test e debugging. Lo scrive senza giri di parole (“se non siete a vostro agio con codice sviluppato dall’AI, questo software non fa per voi”) e racconta una settimana a 14 ore al giorno, contro la sua media di 4-6 dai tempi delle origini di Redis. È un esempio concreto, e onesto, di cosa significa oggi costruire software di sistema complesso affiancati da un LLM di frontiera: senza quell’aiuto, dice, “non puoi costruire DS4 in una settimana, e anche con tutto questo aiuto devi saper parlare con gentilezza agli LLM”.
Cosa ne pensiamo
La frase con cui antirez chiude il suo post è, di fatto, una tesi che portiamo avanti da tempo: “l’AI è troppo critica per essere solo un servizio fornito”. DS4 è la dimostrazione pratica che il pavimento operativo si può possedere: un modello a pesi aperti quasi di frontiera che gira sul proprio hardware, senza dipendere da una API che qualcun altro può limitare o spegnere.
Il tempismo aiuta a vedere il quadro. Nelle ultime settimane abbiamo raccontato come un governo possa ordinare lo spegnimento di un modello closed (il caso Fable 5) e come l’accesso alla frontiera stia diventando un processo filtrato a monte (GPT-5.6 Sol). Sul fronte opposto, i modelli a pesi aperti (come GLM 5.2) e strumenti come ds4 rendono quella indipendenza non solo auspicabile, ma praticabile oggi, su un Mac o su una “GPU in scatola”. È il senso di Open Intelligence, Secure Governance: le parti dello stack AI che non ci si può permettere di vedere disattivate vanno possedute.
Restano i limiti, che antirez non nasconde: è codice beta, esiste da pochi giorni, vincolato ai GGUF forniti e legato a un modello che per scelta cambierà nel tempo. E l’esperienza migliore richiede comunque hardware di fascia alta (96-128 GB di memoria unificata). Ma la traiettoria è quella giusta, ed è esattamente la direzione in cui crediamo: AI on-premise, governata (anche con Admina, che porta audit e policy su qualunque modello, locale o remoto) e sovrana. Un quasi-frontier model sul portatile, qualche mese fa, sembrava fantascienza. Oggi è un make e un ./ds4.