

Artificial Intelligence
On-premise AI architectures, local LLMs, RAG, autonomous agents. The intelligence you can’t afford to see switched off should be owned.
Discover →
Open Source
noze’s contribution to the Open Source ecosystem: projects, tools and publications released under permissive licences.
Discover →
Admina Enterprise
Open Source AI governance: audit trail, PII redaction, bidirectional ALLOW/BLOCK/REDACT policies on any model, local or remote.
Discover Admina →
Research & Development
Applied research and prototyping, from AI to infrastructure, in partnership with universities and research centres.
Discover →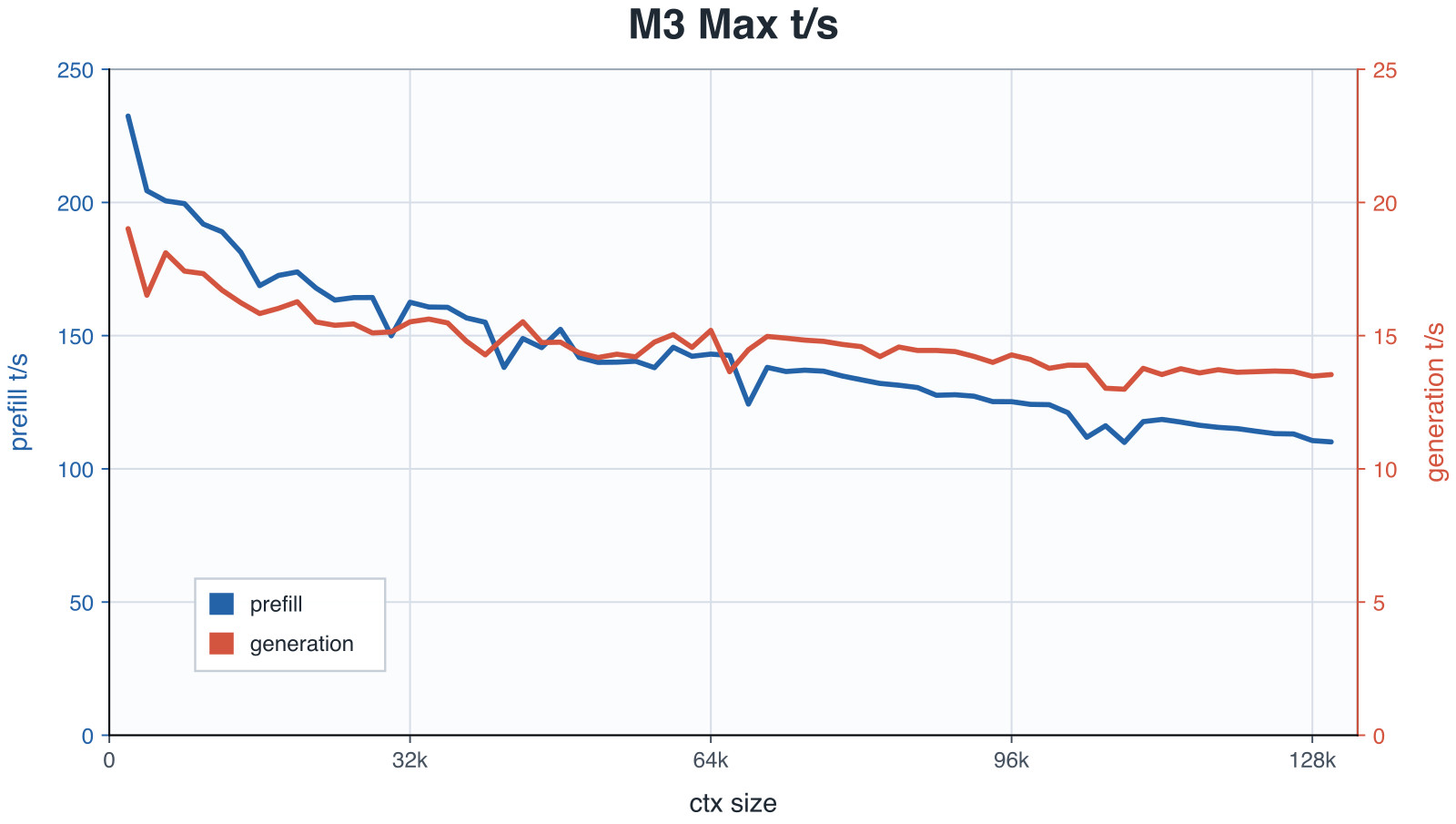
What DwarfStar 4 is
DwarfStar 4 (ds4) is a native inference engine written by antirez (Salvatore Sanfilippo, the creator of Redis), optimized to run DeepSeek V4 Flash locally, with support for DeepSeek V4 PRO on high-memory machines. It is not a generic GGUF runner nor a wrapper around another runtime: it is completely self-contained, a deliberately narrow bet on one model at a time.
The stated goal is a local AI experience that feels “finished” end to end: model loading, prompt rendering, tool calling, KV cache handling (in RAM and on disk), an API server and an integrated coding agent, ready to use from the CLI or from coding agents. The code is released under the MIT licence and written mostly in C, with kernels for Metal (macOS, the primary target), CUDA (including the DGX Spark) and ROCm (Strix Halo, like the Framework Desktop). The project explicitly acknowledges its debt to llama.cpp and GGML.
In short: it takes a near-frontier open-weight model and makes it run well on a high-end personal computer.
The technical bet: 2 bits, done right
What makes ds4 interesting is the asymmetric 2-bit quantization. Instead of compressing everything uniformly, ds4 aggressively quantizes only the routed MoE (Mixture of Experts) experts, which take up most of the model’s space, while leaving the more delicate components untouched (shared experts, projections, routing). antirez describes it as an “extremely asymmetric 2/8 bit quant recipe”, which lets the model fit in 96 or 128 GB of RAM.
The result is not a toy. On the project’s own benchmarks, on a MacBook Pro M3 Max generation holds around 13-15 tokens per second and prefill stays above 100 tokens per second, up to 128k tokens of context (see the chart above). These are the project’s figures, to be read as indicative of that specific hardware, but more than enough for real use.
The KV cache as a “disk citizen”
There is one architectural idea worth highlighting. ds4 treats the KV cache as a first-class citizen of the disk, not just of RAM. By combining DeepSeek V4’s compressed KV caches with the very fast SSDs of modern Macs and SSD streaming, the amount of RAM stops being a wall (“can I run this model or not?”) and becomes a continuous spectrum of speed levels. It is a shift in perspective that greatly widens the set of machines on which a large model is practical, and it pairs well with “GPU in a box” hardware like the DGX Spark we already wrote about regarding on-premise AI workstations.
The project also includes OpenAI- and Anthropic-compatible APIs, tool calling, speculative decoding (MTP), distributed inference across machines, and vector steering to guide the model’s behaviour. It is beta code, built in a few days, but with an already very broad functional footprint.
Built with AI, stated openly
A detail antirez makes explicit: ds4 was developed with strong assistance from GPT 5.5, with humans leading the ideas, testing and debugging. He says so without hedging (“if you are not happy with AI-developed code, this software is not for you”) and recounts a week of 14-hour days, against his usual 4-6 since the early Redis days. It is a concrete, honest example of what it means today to build complex systems software alongside a frontier LLM: without that help, he says, “you can’t build DS4 in one week, and even with all this help you need to know how to gently talk to LLMs”.
Our take
The line antirez closes his post with is, in fact, a thesis we have argued for some time: “AI is too critical to be just a provided service”. DS4 is the practical demonstration that the operational floor can be owned: a near-frontier open-weight model running on your own hardware, with no dependency on an API that someone else can restrict or switch off.
The timing helps see the picture. In recent weeks we have covered how a government can order the shutdown of a closed model (the Fable 5 case) and how access to the frontier is becoming a process gated upstream (GPT-5.6 Sol). On the opposite side, open-weight models (like GLM 5.2) and tools like ds4 make that independence not only desirable but practical today, on a Mac or a “GPU in a box”. This is the point of Open Intelligence, Secure Governance: the parts of the AI stack you can’t afford to see switched off should be owned.
The limits remain, and antirez does not hide them: it is beta code, it has existed for a few days, it is bound to the provided GGUFs and tied to a model that will change over time by design. And the best experience still requires high-end hardware (96-128 GB of unified memory). But the trajectory is the right one, and it is exactly the direction we believe in: on-premise AI, governed (including with Admina, which brings audit and policy to any model, local or remote) and sovereign. A quasi-frontier model on a laptop, a few months ago, looked like science fiction. Today it is a make and a ./ds4.